








The International Executive MBA is designed to solve the most critical challenges faced by leaders like you in a globalised and constantly changing business env
 Blog
Blog
06 de October de 2025
When is it better to use correlation rather than causality?

Sumario:
Statistics, as the science of data, deals with the collection, structuring, analysis, and interpretation of data, particularly when variability and uncertainty are inherent. Some of these concepts are becoming very popular in marketing, but they can also be used in other fields; some of them have come from medicine, for example.
We can make decisions with a higher probability of success based on data.
What is a correlation?
Let's start by talking about what correlations are, which are simply the relationship between two or more variables. This point is important because we can control, for example, the relationship between the number of visits to our website and conversions. For example, the more visits a user makes to our website, the more likely they are to convert.
What methods can we use for correlations?
We have several ways to calculate these correlations in our projects. Below, we will look at the most well-known and widely used methods for calculating correlations.
Covariance:
Covariance shows us what relationship there may be between two variables. In this case, if the result is positive, it is because the relationship between the highest value of variable 1 and the highest value of variable 2 is related, and we can see that they behave similarly.
Conversely, if the high values are related to the minimum values, this will give us a negative value. If, on the other hand, we had a value of 0, this means that there is no relationship between the variables.
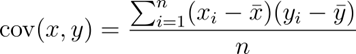
Pearson's correlation coefficient:
The Pearson's correlation coefficient is a linear relationship between two variables. The difference between Pearson's correlation and covariance is that it is independent of the measurement scale of the variables.
We use this correlation to define the degree of relationship between two variables as long as they are quantitative and continuous.
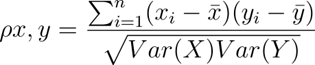
If the value resulting from applying the formula is 1, this indicates that the relationship between the two variables is perfect.
In addition, we have another value, the p_value, which tells us whether the correlation we have is statistically significant.
What is the p-value and how is it interpreted?
The p-value is a data point between 0 and 1 that tells us how likely it is to observe certain results under a specific condition. In addition, this data will tell us if they are equal to or more unusual than the result we obtained in the experiment. With this, we can understand that if the p-value is 0, there is no relationship between the first value and the second.
In short, the p-value is not a probability as such, of whether a hypothesis is true or not, but rather of how likely it is to obtain a result as unusual as the one we see in a case.
Spearman's correlation coefficient:
Spearman's correlation coefficient is a measure of the association between two variables, and we do not need the data to be linear. Let's say that what it does is that when one variable increases or decreases and the second one does too, it indicates that the correlation between the two is high.
Unlike Pearson's correlation, ordinal data can also be used. This makes it less sensitive to extreme or atypical values that we often find in our data.
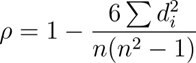
When is it best to use each method?
Covariance measures how two variables vary together and indicates the direction of their relationship (positive or negative). It is not suitable for comparing the intensity of the association because its magnitude depends on the units of measurement. To quantify the strength of a linear relationship between quantitative variables, we use Pearson's correlation, which is recommended when the relationship is approximately linear, there are no relevant outliers, and, ideally, the variables follow a normal distribution. If there are outliers, the relationship is monotonic but not linear, or we are working with ordinal data or non-normal data, Spearman's correlation is preferable.
What is a causal model?
Causal models are tools for representing and explaining how some variables (causes) influence others (effects) within a system. Unlike correlation, which only measures association, causal models allow us to estimate the effect of intervening in one variable on the others.
These causal models are represented by DAGs (directed acyclic graphs), which are nodes where we would see the variables and arrows to indicate cause-and-effect relationships, such as advertising expenditure and sales. Another way to represent them is through structural equations (SEM), which allow us to specify equations that relate causal variables to their effects, including errors or perturbations that explain unobserved variations.
What is causal inference?
Causal inference is the set of methods we use to determine the effect of an action on a specific outcome. Basically, it would answer the question: what would happen if we made this change in the variable?
Randomized experiments:
A randomized controlled trial (RCT) consists of randomly assigning participants to a treatment group or a control group to identify the causal effect. Randomization ensures that, except for receiving the intervention, both groups are comparable on average; thus, any difference in outcomes can be attributed to the treatment.
Quasi-experimental designs:
When we do not have the option of conducting randomized experiments, techniques such as matching, regression discontinuity, or differences in differences (DiD) are used to mimic the conditions of an experiment and control for possible variables.
Matching consists of assigning each subject in the treatment group to one in the control group with similar characteristics. In this way, we try to ensure that the differences observed are due to the treatment applied and not to pre-existing differences.
With discontinuity regression, we take advantage of a natural cut-off point in the data. For example, in marketing, customers who offer a higher score at a certain value could be compared, giving them a benefit. From there, customers who are just above and just below the level would be compared. The idea is that these two groups are very similar except for the fact that they have or have not received the benefit.
Differences in differences analyze the evolution of two groups in two periods, before and after applying the intervention.
Models based on observational data:
This would be the best known, as we also see it in tools such as Google Analytics 4 or Google Ads. Using statistical methods and machine learning algorithms, effects can be estimated from data that does not come from controlled experiments but from historical project data. These include the use of instrumental variables or synthetic control techniques.
Conclusion
Correlation and causation complement each other, but they answer different questions. Correlation (using Pearson or Spearman depending on assumptions) is ideal for exploring and monitoring relationships between variables, prioritizing hypotheses, and detecting patterns; covariance only provides guidance on direction, not on comparable intensity. When the goal is to estimate the effect of an intervention and inform decisions (e.g., “What happens if I increase the advertising budget?”), we need causal models and methods: ideally RCTs, and, when these are not feasible, quasi-experimental designs (matching, discontinuity, DiD) or models with observational data (e.g., instrumental variables or synthetic control) with explicit assumptions. In practice, it is advisable to use correlation to generate and prioritize hypotheses and causal inference to attribute impacts and optimize actions. Thus, the analysis moves from “what moves with what” to “what causes what,” improving the quality of decisions in marketing and other areas.
These can be very powerful tools to consider, for example, in PPC (Pay Per Click) campaigns.
You can find an example of basic code that shows how data interacts at different times: https://github.com/pichu2707/corr-causal-enae
Masters relacionados


Agri-food is a strategic sector for both the national and international economies.



A company or organization that anticipates, identifies needs and threats, foresees, and makes strategic and operational decisions based on Comprehensive Risk Management



In ENAE Business School's Official Master in Logistics and Operations Management program, you will learn how to analyse the performance of a company's operation


The Master in International Trade, E-commerce and AI Concentration is designed to prepare professionals to lead international business operations in a global, d
Artículos recomendados
También te podría interesar leer

Technical expertise gets you in the room. Soft skills determine whether you stay, lead and grow. As automation reshapes entire industries and AI takes over increasingly complex tasks, the one category of competencies that remains distinctly human —…

Most organizations have no shortage of initiatives, what they consistently struggle with is delivering them. Ideas get approved, budgets get allocated, teams get assembled and then something goes wrong. Deadlines slip, costs balloon, scope expands…

These days, most organizations have no shortage of data. What they are short of is the ability to make sense of it. Millions of records flow through business systems every hour and the professionals who can turn that noise into clear, actionable…